在Hadoop 0.20.1版本釋出後,它多了一個名為「TFile」的Binary File Format,因為當初設計「SequenceFile」的Block Compression格式過於複雜,所以重新設計了這個「TFile」檔案格式,同時它也俱備了較佳的效能、可擴充性和語言的中立性(意指不會看到Java中的package名稱,可參考筆者先前po文「Hadoop - Uncompressed SequenceFile Format 詳解」),更多的詳細細節可參考HADOOP-3315。
基本上一個TFile storage format是由兩個部份所組成的:一個是Block Compressed File layer (簡稱BCFile),另一個為TFile-specific <key,value> management layer(這部份未來也許會逐漸地擴充)。而一個BCFile storage layout是由五個部份所組成,它們分別為:
(1)a 16-byte magic.
(2)a data section that consists of a sequence of Data Blocks.
(3)a meta section that consists of a sequence of Meta Blocks.
(4)a Meta Block index section (“Meta Index”).
(5)a tail section.
這裡筆者直接測試一個範例:
import java.io.IOException;
import java.net.URI;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.file.tfile.TFile;
public class TFileWriter
{
private static final String[] DATA = {"One","Two"};
public static void main(String[] args) throws IOException
{
String uri = "hdfs://shen:9000/user/shen/test.tfile";
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(URI.create(uri), conf);
fs.delete(new Path("test.tfile"), true);
Path path = new Path(uri);
FSDataOutputStream fdos = fs.create(path, true);
TFile.Writer writer = new TFile.Writer(fdos, 1024*128, TFile.COMPRESSION_NONE, null , conf);
for (int i = 0; i < DATA.length; i++)
{
writer.append(new byte[]{(byte)i}, DATA[i].getBytes());
}
writer.close();
}
}
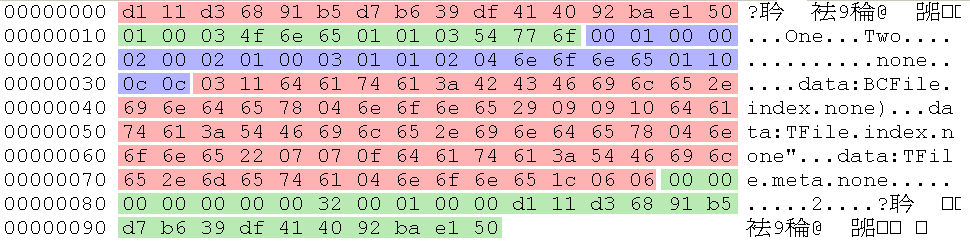
在這個範例中只會有兩筆Record,它們分別為:<0,'One'>和<1,'Two'>,最後輸出成TFile檔案格式,如下圖:
P.S. 下圖筆者用「紅→綠→藍」顏色區隔BCFile storage layout所組成的五個部份。