剛剛在研究一個「Uncompressed SequenceFile Format」檔案,一個個對照Hadoop的原始碼來驗證~ 心得整理如下:
從「Class SequenceFile」所描述的~ 基本上「SequenceFiles」有三種不同的檔案格式~ 它們分別為「Uncompressed SequenceFile Format」、「Record-Compressed SequenceFile Format」和「Block-Compressed SequenceFile Format」,後兩種都是採用壓縮的檔案格式~ 而文本主要介紹剖析「Uncompressed SequenceFile Format」~ 了解這一個檔案格式之後~ 另外兩個自然能得心應手~ 而官方針對這個檔案格式的描述如下:

每一種檔案格式都包含了共同的「SequenceFile Header」用來記錄一些基本資訊~ 如:keyClassName、valueClassName等…
本文以下圖的範例來介紹:
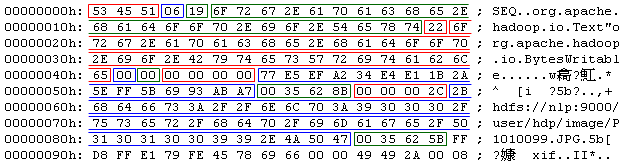
筆者已用「紅→藍→綠」顏色的順序來標記~ 以方便對照~
0x53 0x45 0x51
這是SequenceFile Format的magic header「SEQ」,和一般的檔案格式一樣~ 都是用來判別這個檔案是否屬於「SequenceFile Format」。
0x06
版本編號,目前最新版為「SEQ6」。
0x19 0x6F 0x72 ..... 0x74
這部份屬於keyClassName(Key的類別名稱),而第1個Byte(0x19)用來表示此字串的長度,此範例為「org.apache.hadoop.io.Text」。
0x22 0x6F 0x72 ..... 0x65
這部份屬於valueClassName(Value的類別名稱),第1個Byte(0x22)也是用來表示此字串的長度,此範例為「org.apache.hadoop.io.BytesWritable」。
0x00
是否支援compression?「0x00」=否 (此為Boolean所以佔1個Byte)
0x00
是否支援blockCompression?「0x00」=否(此為Boolean所以佔1個Byte)
0x00 0x00 0x00 0x00
metadata資訊,此範例沒有包含任何「SequenceFile.Metadata」的資訊~ 所以輸出「0x00 0x00 0x00 0x00」(此為Int所以佔4個Bytes),而這四個Bytes也等同於metadata的長度,也就是至少一定會佔用這4個Bytes。
0x77 0xE5 0xEF ..... 0xA7
一個sync標記,用來表示一個「Header」的結束,此標記是亂數產生的~ 從原始碼中可得知此標記是由「new UID()+"@"+time」的方式再進行「MD5」編碼。
0x00 0x35 0x62 0x8B
整筆Record的size~ (此為Int佔4個Bytes),一筆Record包含「Key、Value」的內容資訊。
0x00 0x00 0x00 0x2C
Key內容的size~ (此為Int佔4個Bytes)。
0x2B 0x68 0x64 ..... 0x47
由於筆者用「org.apache.hadoop.io.Text」當Key,所以這裡的資訊是描述一個檔案的路徑名稱,第1個Byte(0x2B)用來表示此字串的長度,內容為「hdfs://nlp:9000/user/hdp/image/P1010099.JPG」。
0x00 0x35 0x62 0x5B
Value內容的size~ (此為Int佔4個Bytes)。
0xFF 0xD8 0xFF .....
筆者以JPEG檔案格式做為介紹~ 所以這裡是「0xFF、0xD8」開頭。
最後~ 雖然Hadoop官網沒有公佈詳細的格式介紹(還是我沒找到?) 希望本文能有所助益。
參考資源
