本文的主旨在於整個Hadoop的環境安裝教學,其它的相關資訊將會另闢說明~
筆者採用目前Hadoop-0.16.4「Stable」版本來建構~
硬體環境
我採用了三台機器來建構,並且為它們都裝上「Debian Linux 4.0r3 (amd64)」的作業系統~ 如下述所示:
主機名稱:hdp-1 IP:192.168.0.10 功能:NameNode、JobTracker、DataNode、TaskTracker
主機名稱:hdp-2 IP:192.168.0.11 功能:DataNode、TaskTracker
主機名稱:hdp-3 IP:192.168.0.12 功能:DataNode、TaskTracker
我在安裝時為這些主機都建立一個名為「hdp」的使用者帳號~
建構步驟
.下載「hadoop-0.16.4.tar.gz」並解壓縮~ 然後搬到「hdp」的家目錄下
wget http://ftp.tcc.edu.tw/pub/Apache/hadoop/core/stable/hadoop-0.16.4.tar.gz tar zxvf hadoop-0.16.4.tar.gz mv hadoop-0.16.4 /home/hdp/
.{重要}修改「三台」主機的「/etc/hosts」,讓彼此的主機名稱和IP位址都能順利地被解析
127.0.0.1 localhost localhost 192.168.0.10 hdp-1 hdp-1 192.168.0.11 hdp-2 hdp-2 192.168.0.12 hdp-3 hdp-3
.接著安裝你的Java環境在「每台機器」上,這裡我們以「jdk1.6.0_06」為例,並將目錄搬移至「/usr/java/」底下
./jdk-6u6-linux-x64.bin mkdir /usr/java mv jdk1.6.0_06 /usr/java/
.「每台機器」請安裝必要的相關軟體,因為Hadoop會透過SSH來啟動和停止各節點的程式
sudo apt-get install ssh
.然後設定你的SSH可以透過公鑰認證的方式來連線,相關細節可參考「鳥哥的Linux 私房菜 - 遠端連線伺服器 Telnet/SSH/XDMCP/VNC/RSH」,筆者在這裡列出我的相關設定
ssh-keygen -t rsa cd /home/hdp/.ssh/ cat id_rsa.pub >> authorized_keys ssh hdp-1
現在應該就不需要密碼即可登入hdp-1本身的機器了~ 不過我們也要利用這樣的方式來登入另外兩台機器,分別為hdp-2、hdp-3,所以請一併地在這兩台機器下的「/home/hdp/」都建立一個「.ssh」的目錄夾,然後用「scp」拷貝「authorized_keys」到這些機器上即可:
sudo scp authorized_keys hdp-2:/home/hdp/.ssh/ sudo scp authorized_keys hdp-3:/home/hdp/.ssh/ ssh hdp-2 ssh hdp-3
.接著開始進行修改Hadoop的相關設定,首先先修改「conf/masters」、「conf/slaves」這兩個設定檔(修改hdp-1即可)。
Secondary NameNode設定:(<HADOOP_HOME>/conf/masters)
hdp-2
Slave設定:(<HADOOP_HOME>/conf/slaves)
hdp-1 hdp-2 hdp-3
.然後修改一下「conf/hadoop-env.sh」來設定Hadoop的環境變數
export JAVA_HOME=/usr/java/jdk1.6.0_06
.接著修改Hadoop的相關參數設定「conf/hadoop-site.xml」,範例如下:
<?xml version="1.0"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <configuration> <property> <name>fs.default.name</name> <value>hdfs://hdp-1:9000/</value> </property> <property> <name>mapred.job.tracker</name> <value>hdp-1:9001</value> </property> <property> <name>dfs.name.dir</name> <value>/home/hdp/dfs/name</value> </property> <property> <name>dfs.data.dir</name> <value>/home/hdp/dfs/data</value> </property> <property> <name>dfs.replication</name> <value>1</value> </property> </configuration>
.最後用「scp」將「hdp-1」的Hadoop整個環境設定及目錄結構拷貝到另外兩台機器上
scp -r /home/hdp/hadoop-0.16.4 hdp-2:/home/hdp/ scp -r /home/hdp/hadoop-0.16.4 hdp-3:/home/hdp/
到這邊大致上就完成屬於你自己的Cloud Computing環境建構了~ 接下來就是啟動Hadoop,並用個小範例來玩玩嚕~
啟動Hadoop
.先格式化一個新的分散式的檔案系統HDFS
<HADOOP_HOME>/bin/hadoop namenode -format
會出現如下所示的相關訊息:
08/06/09 23:45:54 INFO dfs.NameNode: STARTUP_MSG: /************************************************************ STARTUP_MSG: Starting NameNode STARTUP_MSG: host = hdp-1/192.168.0.10 STARTUP_MSG: args = [-format] STARTUP_MSG: version = 0.16.4 STARTUP_MSG: build = http://svn.apache.org/repos/asf/hadoop/core/branches/branch-0.16 -r 652614; compiled by 'hadoopqa' on Fri May 2 00:18:12 UTC 2008 ************************************************************/ 08/06/09 23:45:55 INFO fs.FSNamesystem: fsOwner=hadoop,hadoop,dialout,cdrom,floppy,audio,video,plugdev,netdev,powerdev 08/06/09 23:45:55 INFO fs.FSNamesystem: supergroup=supergroup 08/06/09 23:45:55 INFO fs.FSNamesystem: isPermissionEnabled=true 08/06/09 23:45:55 INFO dfs.Storage: Storage directory /home/hadoop/dfs/name has been successfully formatted. 08/06/09 23:45:55 INFO dfs.NameNode: SHUTDOWN_MSG: /************************************************************ SHUTDOWN_MSG: Shutting down NameNode at hdp-1/192.168.0.10 ************************************************************/
.接著就給它啟動「Hadoop」嚕~
<HADOOP_HOME>/bin/start-all.sh
要驗證所有過程是否無誤~ 可以參閱「<HADOOP_HOME>/logs/」相關的紀錄檔~
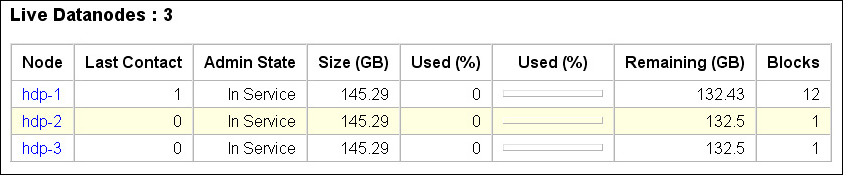
或是開啟NameNode的網頁介面來觀察,若依筆者的設定則需開啟「http://hdp-1:50070/」來觀察,配置正確的話應該有三台DataNode是活著的 ^^v
跑Hadoop範例
這裡我們用官方的一個「WordCount」範例來介紹~
主要建立兩個文字檔,裡頭的單字都用空格來區隔~ 以方便範例程式來運作~
比較重要的是「<HADOOP_HOME>/bin/hadoop dfs -put ./testdata input」,這一行就是用來將「testdata」目錄夾寫入到「HDFS」裡~
mkdir testdata cd testdata echo "hello world bye hello" > file1.txt echo "hadoop hello goodbye hadoop" > file2.txt cd .. <HADOOP_HOME>/bin/hadoop dfs -put ./testdata input
最後就跑給它看嚕~ 看看小飛象能飛得多快~ 哈哈~ ^^b
<HADOOP_HOME>/bin/hadoop jar hadoop-0.16.4-examples.jar wordcount input output
執行結果:
08/06/10 00:03:24 INFO mapred.FileInputFormat: Total input paths to process : 2 08/06/10 00:03:25 INFO mapred.JobClient: Running job: job_200806092347_0001 08/06/10 00:03:26 INFO mapred.JobClient: map 0% reduce 0% 08/06/10 00:03:28 INFO mapred.JobClient: map 33% reduce 0% 08/06/10 00:03:29 INFO mapred.JobClient: map 100% reduce 0% 08/06/10 00:03:35 INFO mapred.JobClient: map 100% reduce 100% 08/06/10 00:03:36 INFO mapred.JobClient: Job complete: job_200806092347_0001 08/06/10 00:03:36 INFO mapred.JobClient: Counters: 12 08/06/10 00:03:36 INFO mapred.JobClient: Job Counters 08/06/10 00:03:36 INFO mapred.JobClient: Launched map tasks=3 08/06/10 00:03:36 INFO mapred.JobClient: Launched reduce tasks=1 08/06/10 00:03:36 INFO mapred.JobClient: Data-local map tasks=1 08/06/10 00:03:36 INFO mapred.JobClient: Map-Reduce Framework 08/06/10 00:03:36 INFO mapred.JobClient: Map input records=2 08/06/10 00:03:36 INFO mapred.JobClient: Map output records=8 08/06/10 00:03:36 INFO mapred.JobClient: Map input bytes=50 08/06/10 00:03:36 INFO mapred.JobClient: Map output bytes=82 08/06/10 00:03:36 INFO mapred.JobClient: Combine input records=8 08/06/10 00:03:36 INFO mapred.JobClient: Combine output records=6 08/06/10 00:03:36 INFO mapred.JobClient: Reduce input groups=5 08/06/10 00:03:36 INFO mapred.JobClient: Reduce input records=6 08/06/10 00:03:36 INFO mapred.JobClient: Reduce output records=5
執行完成之後,我們再將HDFS下的output資料夾抓出來看~
<HADOOP_HOME>/bin/hadoop dfs -get output output cat output/*
輸出的結果就是:
bye 1 goodbye 1 hadoop 2 hello 3 world 1
成功啦~ 恭禧你!! ^^v
要停止Hadoop的運作只要下「bin/stop-all.sh」指令即可~
結論
本文一整個打了很多字~ 如果有介紹未盡詳細的地方,請參閱相關資源~
或是連結到本站的另一篇「一個值得研究的領域 - Hadoop」~
如果在安裝過程之中有任何問題~ 非常歡迎留言討論~ 如果本文有任何謬誤的地方,也請不吝地給予指正,必當感激!!

最近開始STUDY HADOOP
這篇文章幫了我不少
感謝!
2008-07-02 00:19:47
不客氣 ^^ 謝謝你的支持呀!
有機會歡迎常來一起討論唷!! ^^v
2008-07-02 00:27:06
你好,我START HADOOP後
看localhost:50070的網頁
發現LIVE DATA NODE是0
會不會因為我只有一台電腦的關系啊!?
其他的詳細設定這裡不方便貼
你有其他的聯絡方式嗎?
2008-07-22 22:45:09
嗯~ 一台電腦應該也是要看得到Live Datanodes:1,也就是官網上所描述的「Pseudo-Distributed Mode」~ 不過這樣實質意義不大~
我會建議你,如果只是要學習MapReduce programming model,我想是不需要架設Hadoop的~ 用Local Model的方式來練習即可~ 在Windows平臺上用Cygwin模擬來玩~ 否則除非你是要Fully-Distributed Mode才需要架設~
2008-07-23 00:45:12
謝謝大大的建議
我想先在一台電腦試試,之後再加其他電腦進來
架不起來所以沒辦法跑範例有點sad
2008-07-23 11:23:45
不好意思,再請教一下,我看官方的說明文件http://hadoop.apache.org/core/docs/current/quickstart.html
做到這裡時
Copy the input files into the distributed filesystem:
$ bin/hadoop dfs -put conf input
出現的訊息是
08/07/23 14:10:54 WARN fs.FileSystem: "localhost:9000" is a deprecated filesystem name. Use "hdfs://localhost:9000/" instead.
08/07/23 14:10:54 WARN fs.FileSystem: "localhost:9000" is a deprecated filesystem name. Use "hdfs://localhost:9000/" instead.
08/07/23 14:10:54 WARN fs.FileSystem: "localhost:9000" is a deprecated filesystem name. Use "hdfs://localhost:9000/" instead.
08/07/23 14:10:54 WARN fs.FileSystem: "localhost:9000" is a deprecated filesystem name. Use "hdfs://localhost:9000/" instead.
put: Target input/conf is a directory
不知道要取代什麼
他又說conf是資料匣,可是這是官方給的指令
你有遇過這個問題嗎?謝謝
2008-07-23 14:16:24
OK, 我之前用Cygwin跑Hadoop 0.17.1也遇過~
你將「conf/hadoop-site.xml」這個參數檔裡頭的「fs.default.name」、「mapred.job.tracker」兩個參數值將「localhost:9000」、「localhost:9001」改成「hdfs://localhost:9000/」、「hdfs://localhost:9001/」應該就可以了!
good luck!
2008-07-23 15:38:20
不好意思~是否可以請問一下~當我已經正常執行完wordcount的範例之後~在當我使用 "bin/hadoop dfs -get /user/my.username/output ./output.txt" 的指令的時候發現我出現了下列的訊息 "get: null" ~ 請問可能的問題出在哪裡~THX~
PS:我已經使用Web介面看過DataNode裡面~確實存在了output的資料夾~裡面也有個檔案叫 "part-00000" 其內容正好就是執行的結果 ><
2008-08-22 00:35:59
呃... 我沒遇過這樣的情形~
你的環境為何?Hadoop版本?
建議你先測試「bin/hadoop dfs -cat /user/my.username/output/*」看能不能印出你跑完的資料~
還有就是你上述的指令應該是要將「output」目錄下的東西都抓出來~ 所以不太需要給它「.txt」的副檔名~ 除非你只是要抓一個檔出來,例如:「bin/hadoop dfs -get /user/my.username/output/part-00000 ./output.txt」
good luck!
2008-08-22 01:26:34
我的環境是三台 VMWare 的 Fedora core 5 guest
one master + two slave.
JDK = 1.6.7
HADOOP = 0.17.2
後來我發現當我昨天晚上想睡覺~就先將 hadoop shutdown. 然後隔天早上起來再次重起 hadoop. 再試一次就成功了....真是奇怪 ><
2008-08-22 13:41:45
回复6楼:
put: Target input/conf is a directory
的原因可能是以前你的操作已经生成了一个input文件夹,可以换一个名字检验一下
2008-08-22 20:56:55
板大你好~
這幾天我也在架設hadoop
我是使用兩台ubuntu,hadoop 0.18的版本
照著板大所寫的教學後出了一點問題
在namenode(hdp1)的web操作介面上(hdp1:50070)只看的到一個活的node(也就是hdp1自己本身)
無法抓到第二個node(hdp2)
看了一下hdp2的log檔發現似乎是hdp2無法連到hdp1?
(hdp2的authorized_key也要丟給hdp1嗎??)
測試過hdp1可以直接ssh到hdp2不須輸入密碼
hdp2本身使用Pseudo-Distributed MODE也可以work
不知道板大有沒有遇過這種問題可以指點一下
謝謝~
2008-09-30 23:51:01
呃... 抱歉~ 我沒遇過~
而且遺憾的是~ 我目前手邊沒有機器能協助你排解困難~
所以~ 照你如此詳細的描述,我只能建議你再次確認整個設定~ 如:是否整個環境設定及目錄結構都已拷貝到另外的機器上(hdp-2)?
(hdp2的authorized_key也要丟給hdp1嗎??)
不用~
等我有機器時再來裝一下0.18版試試看~
good luck!
2008-10-01 00:10:04
問題終於解決了,原來是port被IPv6綁定住了!害我搞了好幾天@@"想再請問一下板大是否知道web介面中Last Contact這一欄是做什麼用的?在我連到web介面時這一欄會從0~3不規則的變動,不知這樣是否正常?謝謝
2008-10-03 20:05:43
恭禧! ^^
Last Contact確切的目的我目前無法回答你,但是這個值會持續變動是正常的!
有興趣的話,你可以去看它的dfshealth.jsp原始碼:
......(約97~100行)
long timestamp = d.getLastUpdate();
long currentTime = System.currentTimeMillis();
out.print("<td class=\"lastcontact\"> " +
((currentTime - timestamp)/1000) +
或者你也可以下「bin/hadoop dfsadmin -report」來觀察~ 裡頭也有個「Last contact」持續不斷的更新目前的時間~
而上述jsp程式中的變數「d」指的是「DatanodeDescriptor」class,而這個class是繼承「DatanodeInfo」(getLastUpdate()屬於這個class)~
總之就是用來描述「Datanode」的健康情況用的~ ^^ 供您參考
2008-10-03 21:24:01
诸位好:我也按照描述见了一个4台主机的环境,运行wordcount的时候总是出错, 但偶尔也会成功一次,奇怪啊
WARN org.apache.hadoop.mapred.TaskTracker:
getMapOutput(attempt_200810231615_0001_m_000000_0,0) failed :
org.apache.hadoop.util.DiskChecker$DiskErrorException: Could not find taskTracker/jobcache/job_200810231615_0001/attempt_200810231615_0001_m_00000
0_0/output/file.out.index in any of the configured local directories
at
org.apache.hadoop.fs.LocalDirAllocator$AllocatorPerContext.getLocalPathToRead(LocalDirAllocator.java:359)
at
org.apache.hadoop.fs.LocalDirAllocator.getLocalPathToRead(LocalDirAllocator.java:138)
at
org.apache.hadoop.mapred.TaskTracker$MapOutputServlet.doGet(TaskTracker.java:2402)
at javax.servlet.http.HttpServlet.service(HttpServlet.java:689)
at javax.servlet.http.HttpServlet.service(HttpServlet.java:802)
at
org.mortbay.jetty.servlet.ServletHolder.handle(ServletHolder.java:427)
at
org.mortbay.jetty.servlet.WebApplicationHandler.dispatch(WebApplicationHandler.java:475)
at
org.mortbay.jetty.servlet.ServletHandler.handle(ServletHandler.java:567)
at org.mortbay.http.HttpContext.handle(HttpContext.java:1565)
at org.mortbay.jetty.servlet.WebApplicationContext.handle(WebAppl
环境如下:
linux ras2.6.9
hadoop 0.1.8.1
hadoop-site.xml 内容如下:
<configuration>
<property>
<name>fs.default.name</name>
<value>site1:9000</value>
</property>
<property>
<name>mapred.job.tracker</name>
<value>site2:9001</value>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
masters:
site1
site2
slaves:
site3
site4
2008-10-24 11:39:57
我跑wordcount在mapreduce的時間很久然後會出現Too many fetch-failures訊息,這是什麼意思阿??
2009-02-13 15:35:53
請問您的Hadoop版本為何?
在0.15.0版本上這是一個Bug (https://issues.apache.org/jira/browse/HADOOP-1930)
2009-02-13 16:22:30
我用的是0.17.2.1版
不過我只用了兩台PC去架....
這樣有影響嗎??
不過最後也能跑出結果....
只是等了大約20分鐘以上~~
2009-02-13 16:54:15
@Ekin
有幾台Datanode?兩台都是嗎?處理的資料量多大?
還是有更明確的錯誤訊息?
因為我沒遇過這樣的情形,祝你好運!
2009-02-13 18:16:26
Shen大你好...
我在hadoop-site.xml中的設定
....
<property>
<name>fs.default.name</name>
<value>hdp-1:9000</value>
</property>
<property>
<name>mapred.job.tracker</name>
<value>hdp-2:9001</value>
</property>
....
跑程式時卻會發生
ipc.Client: Retrying connect to server: hdp-2:9001. Already tried 1 time(s)
........
如果把mapred.job.tracker設定成hdp-1:9001就沒問題.....
這樣是不就限定namenode和jobtracker要在同一台機器上?
2009-02-18 14:15:06
跑程式時發生的?
這樣的情況會不會在啟動時就已經出現無法連線的問題了,建議你查看一下log file.
先檢查一下「/etc/hosts」確定主機和IP解析是正確無誤的,或是啟動之後開啟「http://hdp-1:50070/」檢查一下有幾台Datanode是活著的。
good luck!
2009-02-19 23:42:41
請問
什麼情況下會找不到Datanode?
我有時會出現這樣的情形,比如原本已經有三台架設好的,且運作也正常,當我再多架一台slave,也修改了conf/slaves,也改了/etc/hosts了,但卻所有的Datanode都找不到了
謝謝
2009-03-20 00:19:26
嗯~ 關於你的問題,由於我目前手上沒有任何的機器與環境,所以沒有辦法協助你解決問題,你可以試著將你的問題丟到hadoop mailing list(http://hadoop.apache.org/core/mailing_lists.html)。
good luck!
2009-03-20 16:55:14
Hi,This a pretty good artical.....
我有一個問題,想請教先進,除了Word Count之外,你對於利用Hadoop去時作其它的功能的方式了解嗎?因為我正在找任何一個範例,是除了Word Count以外的範例
2009-05-25 23:05:12
@VincentHu
WordCount是一個最基本用來解釋MapReduce如何運作的例子,就像學習任何程式中的HelloWorld範例。
Hadoop的應用很廣泛,常見於一些Machine Learning領域(如:Apache Mahout)或是搜尋引擎(Apache Nutch),另外NYT也用它應用於大量批次轉換檔案格式,另外也有像HBase這樣的Distributed Storage System也架構在Hadoop之上,這些都是值得探討的地方。
筆者的部落格也有幾篇應用Hadoop的例子,希望對您有幫助,謝謝。
2009-05-25 23:29:47
可以請問一下嗎 我用 hadoop 0.18.3
vmware架設了三個,形成cloud
在使用瀏覽器觀看時可以順利看到三台電腦
http://<hadoopIP>:50070/dfshealth.jsp
可是我想按 "Browse the filesystem" 卻沒辦法成功看到檔案,找不到解決辦法。可以提供我意見嗎 謝謝
2009-06-17 00:39:58
@tim
我想您可以試著檢查一下領域名稱和IP的對應,或是您可以提供更詳細的說明。
2009-06-17 19:57:25
請問14樓的 shen
你是如何解決在namenode(hdp1)的web操作介面上(hdp1:50070)只看的到一個活的node(也就是hdp1自己本身)
無法抓到第二個node(hdp2)
我也遇到這個問題,可以麻煩你詳細說明一下嗎?
2009-06-24 02:19:03
您好
想請問一下如何在程式指令查詢正在執行中的Job
功能類似bin/hadoop job -list
我是想要用來查詢、啟動、kill Job用的
謝謝
2009-07-29 22:56:02
@28樓的Shen:
我也遇到一樣的問題
安裝了叢集環境的Hadoop
可以開啟 http://IP:50070/dfshealth.jsp的頁面
顯示的Live Nodes數目正確,也都有其他的Cluster Summary
但是當我點選"Browser the filesystem"時
卻會出現找不到此網頁的錯誤訊息
請問要如何查驗問題呢?
也想請問一下,要如何驗證您說的"檢查領域名稱與IP對應"呢?
謝謝
2010-04-09 10:13:13
在你使用瀏覽器的電腦上修改 /etc/hosts (for Linux)
如果是Windows平台請檢查 C:\WINDOWS\system32\drivers\etc\hosts
2010-04-09 11:13:47
@shen
謝謝!
果然是這邊的問題 :P
(之前以為是server的etc/hosts的問題,原來是要改browser上的)
打擾了~
2010-04-09 11:55:03
想要請問Shen大
我在使用hadoop要他跑這一篇所舉的範例時
他會顯示FAILED的訊息
但是奇怪的是雖然在執行的過程中緩慢,可是結果卻是正常的
在使用http://ubuntu01:50070查看Live Nodes狀態時,他的Used率卻都是顯示0%
我把所有的參數列在這裡供Shen大參考
http://www.google.com/notebook/public/17208103153723465626/BDRMZDAoQpNqC8YUl?hl=zh-TW
感恩解惑
2010-05-04 11:13:21
試著修改一下你的/etc/hosts檔案:
將下面這一行:
127.0.1.1 ubuntu01.mshome.net ubuntu01
改成:
127.0.1.1 ubuntu01.mshome.net
拿掉ubuntu01就是了,試試看.
2010-05-04 11:21:35
感恩Shen大
果然/etc/hosts這份文件佔了部份的問題
原先是想說他預設就有這個內容,所以不做更動,
沒想到會造成這樣的錯誤,
雖然他預設這樣寫確實是不對的(內容應該要一個IP對應到一個Hostname)
另外想要請教一些問題:
1、在Hadoop剛Sartart-all.sh時到http://ubuntu01:50070/應會顯示Safe Mode is ON字樣,但是我這裡會一直讀取網頁,遲遲不會顯示任何東西,直到過了約十分鐘後會先出現ubuntu02、和ubuntu03的node訊息(ubuntu01還未出現):
http://cid-f54311d61d5f3f46.skydrive.live.com/self.aspx/.Public/Hadoop/NoSafeMode01.JPG
http://cid-f54311d61d5f3f46.skydrive.live.com/self.aspx/.Public/Hadoop/NoSafeMode02.JPG
直到在過了約5分鐘ubuntu01才會正常顯示:
http://cid-f54311d61d5f3f46.skydrive.live.com/self.aspx/.Public/Hadoop/NoSafeMode03.JPG
http://cid-f54311d61d5f3f46.skydrive.live.com/self.aspx/.Public/Hadoop/NoSafeMode04.JPG
這段等待期http://ubuntu01:50030/與http://ubuntu01:50060/皆在讀取中
2、每一次在執行/opt/hadoop/bin/hadoop namenode -format指令後皆要在將另外兩台機器上面把其datanode tmp檔刪除(rm -rf /opt/hadoop/tmp/hadoop-cookie/dfs/data),否則在start-all的另外兩台的datanode將不會開啟(執行jps後將不會出現datanode)。
感恩解惑
2010-05-04 18:21:07
不好意思上述應該不能稱之為問題,應該是說這兩個現象是否正常
感恩^^
2010-05-04 18:22:29
1. 十分鐘是有點久了點... 第一次啟動Hadoop就如此嗎?詳細的情形要看log檔才知道是怎麼回事。
2. 是的,要格式化hdfs之前都需要將之前的資料刪除。
2010-05-04 18:56:27
了解,詳細情形還在查找
非常感恩Shen大解惑^^
2010-05-10 08:23:06
請問您架設的三台主機的規格是什麼?謝謝!
2010-09-19 20:09:26
to amy:
那些電腦已經不存在了,所以也無從得知。
2010-09-20 00:56:49
請問shen大一個問題
當我都設定好時 要去run wordcount範例程式的時候
我打
bin/hadoop jar hadoop-0.20.2-examples.jar wordcount input ouput
可是終端機的畫面直接停住 任何文字都沒有跑出來 感覺像是死當
可以幫我解惑嗎?謝謝!
2010-12-23 19:08:23
直接停住?我想你直接去看Log檔會比較清楚到底發生什麼情況。
或是回頭再確認一次安裝步驟,例如:是否有格式化?DataNode是否正常啟動等等。
2010-12-23 22:58:02
您好,我剛開始study cloud,讀了很多文章但觀念還是不太清楚
想請問您
如果我只是要用一台個人電腦架設測試用的雲端平台
裝設VMware vSphere4的話
還需要用到Hadoop嗎?
另外Hadoop是直接拿來控管虛擬資源的軟體嗎
可是我看很多人再用JAVA改程式
讓我不太能理解
Hadoop是拿來寫的還是拿來用的呢?
謝謝您
2011-02-12 15:52:43
Dear cathy,
如果你要的是IaaS相關的建置軟體的話,請參考Xen or VMware等軟體,這和Hadoop沒有直接的相關。
Hadoop是一個可讓你用來作大量資料分散式處理或儲存的一個平台,而你需要自行撰寫MapReduce程式,讓它在Hadoop的平台上執行,執行的結果會儲存在HDFS的分散式檔案系統中。
2011-02-14 08:43:02
您好^^
我在Windows平臺上用Cygwin模擬hadoop0(當作master&slave),
另外也利用vmware架設2台主機hadoop1,hadoop2(當作slave),
start=all.sh之後
http://140.118.20.81:50030的node數為3,
但是http://140.118.20.81:50070的live datanode數為1,
而且node名稱會一直變動(ex.haddop0->hadoop1->haddop2->....)
請問是什麼原因呢??
是因為實際上使用的電腦只有一台嗎???
2011-09-04 16:50:36
Dear Betty,
如果你只是想玩MapReduce的話,建議採用Local Mode Hadoop即可,若你想測試實際的Hadoop Cluster,還是建議用獨立的機器去玩.. 用VM去跑有點不切實際
2011-09-05 09:24:30
你好,請問我是使用VM裡的terminal來輸入,可是才到"修改「三台」主機的「/etc/hosts」"這個步驟時就卡住了,我沒有辦法輸入指令去修改這部分的資料,可以請問輸入的步驟跟指令有哪些嗎?謝謝你
2011-10-10 13:17:42
@carina
sudo vim /etc/hosts
2011-10-11 10:26:00
你好,不好意思,我的意思是我在輸入sudo vim /etc/hosts並輸入密碼之後進去的畫面,沒有辦法做修改,請問這邊應該輸入什麼指定呢?謝謝你
2011-11-17 07:06:31
@carina
權限不夠?還是忘了切換到「編輯」模式?
2011-11-17 09:02:46
大大你好:
我照著你的說明安裝2台機器,但是live node都只有顯示1
我已經有關閉ipv6用下面這條指令
HADOOP_OPTS=-Djava.net.preferIPv4Stack=true
但是還是不行,請問一下要如何解決?
2012-02-04 17:53:24
@apple
建議先查一下兩台 datanode 的 log,這樣比較有辦法除錯。
2012-02-06 09:18:15
我是用hadoop-0.20.2的版本
他好像將hadoop-site.xml給拆成mappred-site.xml core-site.xml hdfs-site.xml
請問mappred-site.xml的內容是否為
property>
<name>mapred.job.tracker</name>
<value>hdp-1:9001</value>
</property>
hdfs-site.xml內容是否為
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
core-site.xml內容是否為
<property>
<name>fs.default.name</name>
<value>hdfs://hdp-1:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hdp/dfs/data</value>
</property>
比較有疑問的是我並沒有/home/hdp/dfs/data這個資料夾
是要自行建立嗎?
謝謝
2012-02-06 12:45:31
@apple
> 比較有疑問的是我並沒有/home/hdp/dfs/data這個資料夾是要自行建立嗎?
您可以修改成自己有寫入權限的路徑。這篇文章是用 hdp 這個身份去執行 hadoop。
2012-02-06 13:46:14
Q1:所以只要指定成有寫入權限的路徑就好了?
Q2:可以幫忙解釋一下這個property的作用嗎?
2012-02-06 15:28:16
A1: 是的,假設您的身份是 apple ,那可以指定成 /home/apple/dfs。然後 mkdir -p ~/hadoop 剩下的執行 start-all.sh 時就會把 mapred 跟 dfs 等目錄建起來。
A2: hadoop.tmp.dir 跟另外四個參數有關,也就是存放 namenode, jobtracker, datanode, tasktracker, secondarynamenode 的目錄預設值都跟 hadoop.tmp.dir 有關。
參數說明詳 http://hadoop.apache.org/common/docs/current/core-default.html
http://hadoop.apache.org/common/docs/current/hdfs-default.html
dfs.name.dir 預設值 ${hadoop.tmp.dir}/dfs/name
dfs.data.dir 預設值 ${hadoop.tmp.dir}/dfs/data
http://hadoop.apache.org/common/docs/current/mapred-default.html
mapred.local.dir 預設值 ${hadoop.tmp.dir}/mapred/local
mapred.system.dir 預設值 ${hadoop.tmp.dir}/mapred/system
mapred.temp.dir 預設值 ${hadoop.tmp.dir}/mapred/temp
2012-02-07 17:22:44
想問一下 我想用這個軟體來做像是 google這種搜尋引擎
例如:我放1000筆圖片在這資料庫 而我要找第N個圖
這個軟體做得到嗎><?
2012-02-21 22:16:55
Hadoop是用來分散式處理,你的需求比較像是需要HBase
2012-02-22 14:50:25
我描述有點錯誤
應該說我想要在雲端建立個圖庫 將圖片運算後再傳回PC(甚至是手機)
在網路上看過些paper
JSP應該就能做到這樣吧?
還是一定要hadoop或是hbase這種程式呢?
2012-02-23 09:10:34
不一定需要Hadoop或HBase, 除非量很大,否則資料庫可能就可以簡單的應用。
2012-02-24 16:11:21
我現在是在做專題
很謝謝你提供這麼多資訊及耐心回答
不知道你願不願意再跟我多透露點訊息
就是以圖書系統為例好像比較多是資料庫 然後對資料裡做查詢
那如果說今天是圖片呢?
Amazon好像做過從手機拍一本書 再從資料庫尋找就能知道這本書的價錢
我想問的是如果說今天我也想做小型的這種資料庫
我是有想說用access 但是好像mysql比較OK是這樣嗎?
能否給點方向 或是該看什麼書籍
謝謝你
2012-02-24 23:00:39
以圖書系統為例,一般都是掃描 ISBN 條碼來取得書籍的描述。這是最容易做的方式。
如果要作到拍書皮封面,比對圖片書籍,技術上會需要:
(1) 所有書籍的封面 -> 經過圖形辨識產生每張圖的特徵值(RGB, 邊緣外框, 形狀等) -> 存到資料庫供後續比對用 (DataSet A)
(2) 手機上傳圖片 -> 經過相同的圖形辨識程式,產生目標圖的特徵值。(DataSet B)
(3) 將 DataSet B 與 DataSet A 進行兩兩比對,計算相似度(您必須自行定義相似度的計算方式),然後根據相似度分數高低,列出對應的圖書資料。
2012-02-27 12:00:07
不好意思...
我想請問一下,就是我最近開始在大學專題
也是第一次接觸hadoop這個軟體(ubuntu)
使用了一台NameNode,兩台DataNode
專題老師要求我們將些許資料匯入到DataNode裡
但我們還不熟hadoop...
所以想請問一下,我們該使用甚麼資料庫去儲存資料
是Hbase 還是 MySQL 還是有較符合初學者使用的資料庫可以儲存資料呢?
感謝^^
2012-03-09 22:49:18
Hadoop 的 DataNode 是檔案系統,就像您電腦的檔案總管。
負責存放的是「檔案」。因此老師要求您放些許資料到 DataNode,應該是放「檔案」。
雖然 HBase 是基於 Hadoop HDFS 的資料庫,但它的 Key-Value 設計可能與過去大家學的 MySQL 關聯式資料庫(Rational Database)觀念相差非常多,也沒有標準 SQL 語法可用。使用前請三思,莫為了「用」而用。
- Jazz
2012-03-11 01:02:01
請問一下...
如果我是在兩台DataNode中使用MySQL來存放資料...
再由NameNode來抓取資料 會不會有任何問題
不好意思...因為是新手很多資料的不清楚~
2012-03-11 16:25:44
只能說 datanode 跟 mysql 是兩回事....
一個是檔案系統,一個是資料庫。
資料庫雖然是裝在檔案系統之上,但 MySQL 硬是要裝在 HDFS 上,
條件是要把 HDFS 掛載起來,況且這樣做效能也不好。
2012-03-12 14:30:59