本文的主旨在於整個Hadoop的環境安裝教學,其它的相關資訊將會另闢說明~
筆者採用目前Hadoop-0.16.4「Stable」版本來建構~
硬體環境
我採用了三台機器來建構,並且為它們都裝上「Debian Linux 4.0r3 (amd64)」的作業系統~ 如下述所示:
主機名稱:hdp-1 IP:192.168.0.10 功能:NameNode、JobTracker、DataNode、TaskTracker
主機名稱:hdp-2 IP:192.168.0.11 功能:DataNode、TaskTracker
主機名稱:hdp-3 IP:192.168.0.12 功能:DataNode、TaskTracker
我在安裝時為這些主機都建立一個名為「hdp」的使用者帳號~
建構步驟
.下載「hadoop-0.16.4.tar.gz」並解壓縮~ 然後搬到「hdp」的家目錄下
wget http://ftp.tcc.edu.tw/pub/Apache/hadoop/core/stable/hadoop-0.16.4.tar.gz
tar zxvf hadoop-0.16.4.tar.gz
mv hadoop-0.16.4 /home/hdp/
.{重要}修改「三台」主機的「/etc/hosts」,讓彼此的主機名稱和IP位址都能順利地被解析
127.0.0.1 localhost localhost
192.168.0.10 hdp-1 hdp-1
192.168.0.11 hdp-2 hdp-2
192.168.0.12 hdp-3 hdp-3
.接著安裝你的Java環境在「每台機器」上,這裡我們以「jdk1.6.0_06」為例,並將目錄搬移至「/usr/java/」底下
./jdk-6u6-linux-x64.bin
mkdir /usr/java
mv jdk1.6.0_06 /usr/java/
.「每台機器」請安裝必要的相關軟體,因為Hadoop會透過SSH來啟動和停止各節點的程式
sudo apt-get install ssh
.然後設定你的SSH可以透過公鑰認證的方式來連線,相關細節可參考「鳥哥的Linux 私房菜 - 遠端連線伺服器 Telnet/SSH/XDMCP/VNC/RSH」,筆者在這裡列出我的相關設定
ssh-keygen -t rsa
cd /home/hdp/.ssh/
cat id_rsa.pub >> authorized_keys
ssh hdp-1
現在應該就不需要密碼即可登入hdp-1本身的機器了~ 不過我們也要利用這樣的方式來登入另外兩台機器,分別為hdp-2、hdp-3,所以請一併地在這兩台機器下的「/home/hdp/」都建立一個「.ssh」的目錄夾,然後用「scp」拷貝「authorized_keys」到這些機器上即可:
sudo scp authorized_keys hdp-2:/home/hdp/.ssh/
sudo scp authorized_keys hdp-3:/home/hdp/.ssh/
ssh hdp-2
ssh hdp-3
.接著開始進行修改Hadoop的相關設定,首先先修改「conf/masters」、「conf/slaves」這兩個設定檔(修改hdp-1即可)。
Secondary NameNode設定:(<HADOOP_HOME>/conf/masters)
hdp-2
Slave設定:(<HADOOP_HOME>/conf/slaves)
hdp-1
hdp-2
hdp-3
.然後修改一下「conf/hadoop-env.sh」來設定Hadoop的環境變數
export JAVA_HOME=/usr/java/jdk1.6.0_06
.接著修改Hadoop的相關參數設定「conf/hadoop-site.xml」,範例如下:
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://hdp-1:9000/</value>
</property>
<property>
<name>mapred.job.tracker</name>
<value>hdp-1:9001</value>
</property>
<property>
<name>dfs.name.dir</name>
<value>/home/hdp/dfs/name</value>
</property>
<property>
<name>dfs.data.dir</name>
<value>/home/hdp/dfs/data</value>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
.最後用「scp」將「hdp-1」的Hadoop整個環境設定及目錄結構拷貝到另外兩台機器上
scp -r /home/hdp/hadoop-0.16.4 hdp-2:/home/hdp/
scp -r /home/hdp/hadoop-0.16.4 hdp-3:/home/hdp/
到這邊大致上就完成屬於你自己的Cloud Computing環境建構了~ 接下來就是啟動Hadoop,並用個小範例來玩玩嚕~
啟動Hadoop
.先格式化一個新的分散式的檔案系統HDFS
<HADOOP_HOME>/bin/hadoop namenode -format
會出現如下所示的相關訊息:
08/06/09 23:45:54 INFO dfs.NameNode: STARTUP_MSG:
/************************************************************
STARTUP_MSG: Starting NameNode
STARTUP_MSG: host = hdp-1/192.168.0.10
STARTUP_MSG: args = [-format]
STARTUP_MSG: version = 0.16.4
STARTUP_MSG: build = http://svn.apache.org/repos/asf/hadoop/core/branches/branch-0.16 -r 652614; compiled by 'hadoopqa' on Fri May 2 00:18:12 UTC 2008
************************************************************/
08/06/09 23:45:55 INFO fs.FSNamesystem: fsOwner=hadoop,hadoop,dialout,cdrom,floppy,audio,video,plugdev,netdev,powerdev
08/06/09 23:45:55 INFO fs.FSNamesystem: supergroup=supergroup
08/06/09 23:45:55 INFO fs.FSNamesystem: isPermissionEnabled=true
08/06/09 23:45:55 INFO dfs.Storage: Storage directory /home/hadoop/dfs/name has been successfully formatted.
08/06/09 23:45:55 INFO dfs.NameNode: SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode at hdp-1/192.168.0.10
************************************************************/
.接著就給它啟動「Hadoop」嚕~
<HADOOP_HOME>/bin/start-all.sh
要驗證所有過程是否無誤~ 可以參閱「<HADOOP_HOME>/logs/」相關的紀錄檔~
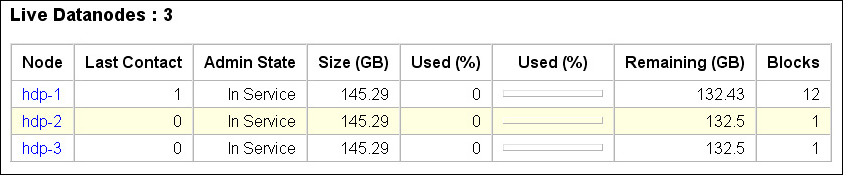
或是開啟NameNode的網頁介面來觀察,若依筆者的設定則需開啟「http://hdp-1:50070/」來觀察,配置正確的話應該有三台DataNode是活著的 ^^v
跑Hadoop範例
這裡我們用官方的一個「WordCount」範例來介紹~
主要建立兩個文字檔,裡頭的單字都用空格來區隔~ 以方便範例程式來運作~
比較重要的是「<HADOOP_HOME>/bin/hadoop dfs -put ./testdata input」,這一行就是用來將「testdata」目錄夾寫入到「HDFS」裡~
mkdir testdata
cd testdata
echo "hello world bye hello" > file1.txt
echo "hadoop hello goodbye hadoop" > file2.txt
cd ..
<HADOOP_HOME>/bin/hadoop dfs -put ./testdata input
最後就跑給它看嚕~ 看看小飛象能飛得多快~ 哈哈~ ^^b
<HADOOP_HOME>/bin/hadoop jar hadoop-0.16.4-examples.jar wordcount input output
執行結果:
08/06/10 00:03:24 INFO mapred.FileInputFormat: Total input paths to process : 2
08/06/10 00:03:25 INFO mapred.JobClient: Running job: job_200806092347_0001
08/06/10 00:03:26 INFO mapred.JobClient: map 0% reduce 0%
08/06/10 00:03:28 INFO mapred.JobClient: map 33% reduce 0%
08/06/10 00:03:29 INFO mapred.JobClient: map 100% reduce 0%
08/06/10 00:03:35 INFO mapred.JobClient: map 100% reduce 100%
08/06/10 00:03:36 INFO mapred.JobClient: Job complete: job_200806092347_0001
08/06/10 00:03:36 INFO mapred.JobClient: Counters: 12
08/06/10 00:03:36 INFO mapred.JobClient: Job Counters
08/06/10 00:03:36 INFO mapred.JobClient: Launched map tasks=3
08/06/10 00:03:36 INFO mapred.JobClient: Launched reduce tasks=1
08/06/10 00:03:36 INFO mapred.JobClient: Data-local map tasks=1
08/06/10 00:03:36 INFO mapred.JobClient: Map-Reduce Framework
08/06/10 00:03:36 INFO mapred.JobClient: Map input records=2
08/06/10 00:03:36 INFO mapred.JobClient: Map output records=8
08/06/10 00:03:36 INFO mapred.JobClient: Map input bytes=50
08/06/10 00:03:36 INFO mapred.JobClient: Map output bytes=82
08/06/10 00:03:36 INFO mapred.JobClient: Combine input records=8
08/06/10 00:03:36 INFO mapred.JobClient: Combine output records=6
08/06/10 00:03:36 INFO mapred.JobClient: Reduce input groups=5
08/06/10 00:03:36 INFO mapred.JobClient: Reduce input records=6
08/06/10 00:03:36 INFO mapred.JobClient: Reduce output records=5
執行完成之後,我們再將HDFS下的output資料夾抓出來看~
<HADOOP_HOME>/bin/hadoop dfs -get output output
cat output/*
輸出的結果就是:
bye 1
goodbye 1
hadoop 2
hello 3
world 1
成功啦~ 恭禧你!! ^^v
要停止Hadoop的運作只要下「bin/stop-all.sh」指令即可~
結論
本文一整個打了很多字~ 如果有介紹未盡詳細的地方,請參閱相關資源~
或是連結到本站的另一篇「一個值得研究的領域 - Hadoop」~
如果在安裝過程之中有任何問題~ 非常歡迎留言討論~ 如果本文有任何謬誤的地方,也請不吝地給予指正,必當感激!!