前陣子在寫這個Blog的時候,發現一個惱人的問題~
由於我都是用UTF-8做為編碼(notepad編輯),然而在使用include時,在IE的網頁上卻會自動地多一個斷行,這會造成網頁排版上的不一致(FireFox沒有這樣的問題),範例如下:
index.jsp
<%@page language="java" contentType="text/html;charset=utf-8"%> <html> <head> <meta http-equiv="Content-Type" content="text/html;charset=utf-8"> </head> <body> <jsp:include page="a.jsp"/> </body> </html>
a.jsp
<%@page language="java" contentType="text/html;charset=utf-8"%> <p>Welcome to Ring's Blog</p>
在IE上看到的情況是:
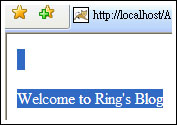
網頁上的原始檔如下:
<html> <head> <meta http-equiv="Content-Type" content="text/html;charset=utf-8"> </head> <body> <p>Welcome to Ring's Blog</p> </body> </html>
Tomcat剖析後所產生的a_jsp.java檔

後來直接將UTF-8編碼中的前三個位元刪除,也就是刪除Byte Order Mark(BOM)即可,它可用來辨識你的文件是哪一種編碼,不過有些編輯器是不會加上的~
Byte Order Mark
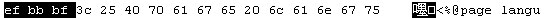

I haven't understood well If BOM could be used for URL too or only for filenames.
Thank you
2008-01-28 15:45:27
As far as I know, it's just only for file encoding.
2008-01-28 20:03:42