
當兩隻大象結合的時候... 說實在的,這個標題我想很難讓人聯想到這意含為何.. 加上Goolge搜尋引擎對於網頁中的「title元素」所佔的權重又比較高... 嗯~ 所以本文似乎不容易被搜尋得到... 天曉得這是一篇探討Hadoop結合PostgreSQL的文章.. 不過我還是想這麼做...
以往要將資料庫中的資料抓出來當作MapReduce的輸入/輸出都必須先自行處理這當中的轉換工作,而本文要探討的是直接採用資料庫當作MapReduce的輸入/輸出資料,因為這在Hadoop 0.19版(目前為0.19.1)就納入支援了「MapReduce for MySQL(Hadoop-2536)」,底下是一個簡單的測試範例,下述是筆者自行建立的「wordcount」資料表:
CREATE TABLE wordcount ( id serial NOT NULL, word character varying(20) NOT NULL, count integer NOT NULL DEFAULT 1, CONSTRAINT wc_id PRIMARY KEY (id) ) WITH (OIDS=FALSE); ALTER TABLE wordcount OWNER TO postgres;
預設的資料內容如下:
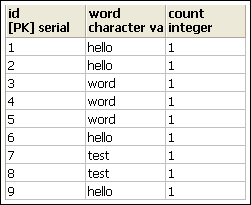
基本上就是先透過DBConfiguration去設定資料庫相關的組態工作,然後交由DBInputFormat和DBOutputFormat來處理相對應資料表的輸入和輸出,並且撰寫一個實作DBWritable介面的Class,用來作為資料庫讀/寫工作的橋梁,在這個範例中為「WordRecord」Class,詳細請參考附檔。
P.S. 請拷貝一份「JDBC」driver放置在「HADOOP_HOME/lib」底下,另外您執行的jar檔也需要一同打包這個driver。
import java.io.IOException;
import java.util.Iterator;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapred.JobClient;
import org.apache.hadoop.mapred.JobConf;
import org.apache.hadoop.mapred.MapReduceBase;
import org.apache.hadoop.mapred.Mapper;
import org.apache.hadoop.mapred.OutputCollector;
import org.apache.hadoop.mapred.Reducer;
import org.apache.hadoop.mapred.Reporter;
import org.apache.hadoop.mapred.lib.db.DBConfiguration;
import org.apache.hadoop.mapred.lib.db.DBInputFormat;
import org.apache.hadoop.mapred.lib.db.DBOutputFormat;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
public class WordCount extends Configured implements Tool
{
public int run(String[] arg0) throws Exception
{
JobConf job = new JobConf(getConf(), WordCount.class);
job.setJobName("DBWordCount");
job.setMapperClass(WordCountMapper.class);
job.setReducerClass(WordCountReducer.class);
DBConfiguration.configureDB(job, "org.postgresql.Driver", "jdbc:postgresql://localhost/WordCount", "帳號", "密碼");
String[] fields = { "word", "count" };
DBInputFormat.setInput(job, WordRecord.class, "wordcount", null, "id", fields);
DBOutputFormat.setOutput(job, "wordcount(word,count)", fields);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
job.setOutputKeyClass(WordRecord.class);
job.setOutputValueClass(NullWritable.class);
JobClient.runJob(job);
return 0;
}
static class WordCountMapper extends MapReduceBase implements
Mapper<LongWritable, WordRecord, Text, IntWritable>
{
public void map(LongWritable key, WordRecord value,
OutputCollector<Text, IntWritable> output, Reporter reporter) throws IOException
{
output.collect(new Text(value.word), new IntWritable(value.count));
}
}
static class WordCountReducer extends MapReduceBase implements
Reducer<Text, IntWritable, WordRecord, NullWritable>
{
public void reduce(Text key, Iterator<IntWritable> values,
OutputCollector<WordRecord, NullWritable> output,
Reporter reporter) throws IOException
{
int sum = 0;
while (values.hasNext())
{
sum += values.next().get();
}
output.collect(new WordRecord(key.toString(), sum), NullWritable.get());
}
}
public static void main(String args[]) throws Exception
{
int ret = ToolRunner.run(new WordCount(), args);
System.exit(ret);
}
}
結果:(直接寫回wordcount資料表)

詳細的內部實作可以參考DBInputFormat和DBOutputFormat,會發現DBInputFormat中的「getSelectQuery()」方法裡面用了select... order by、limit、offset去串起來這樣的SQL語法(所以目前尚不支援某些資料庫,如:Oracle),相反的DBOutputFormat當然就是用insert into tablename values(fields name),而在此範例中雖然有一個serial number當作Primary Key(id),不過筆者所撰寫的「WordRecord」並沒有去操作這個ID,所以在「setOutput」的方法中筆者明確地告知資料表名稱為「wordcount(word,count)」,如此在輸出到資料表時才不會出錯。
.原始檔
參考資源

